
1yr with AX7 Data Management – My top 12 learnings
Updated 26 January 2024
We’re so used to the speed of current evolvements around Microsoft Dynamics AX (or should I say Dynamics 365 ;-)), that most of us who are interested in integrations have familiarized themselves for long with concepts like data entities and entity stores. In this blog post, I would like to go beyond the ‘obvious’ by sharing 1 year of personal project experience in working with AX7 Data Management.
To enable you to quickly scan this blog post according to your own points of interest, I have listed my experiences in a top 10-alike pattern in random order.
One year with AX7 Data Management: My top 12 learnings
-
How to be really sure that code changes have been effectuated for data entities
I’ve seen a lot of situations where a data entity, after updating the code for an AX7 data entity, showed unexpected behavior. In most cases, the people releasing the software had not forgotten to click the Refresh data entities button in the AX7 Data Management’s Framework parameters after release. As it turned out, this is not always sufficient. I apply the following procedure which never failed me so far: -
Delete the mappings on data projects which build upon the data entities to be refreshed (this is required for step 2).
• Note: in a typical project, multiple data projects may exist building upon a single data entity. This table browser query will help you find the respective data projects quickly: https:///Default.htm?mi=SysTableBrowser&prt=initial&cmp= &tablename=DMFDefinitionGroupEntity&limitednav=true -
Delete all the data entities from the Data entities list which are software updated.
-
Now refresh data entities through System administration > Workspaces > Data management > Framework parameters > Refresh data entities. The deleted entities will re-appear.
-
Re-create the mappings w you deleted earlier.
2. Public cloud versus OneBox behavior
Most DEV environments and even TEST environments will be based on OneBox installations. This is either a local VM with all AX7 components running on premise through Azure authentication or similar VM hosted on Azure. The differences in behavior between these SQL Server OneBox environments and Azure SQL powered Public Cloud environments are decreasing by the minute due to bug fixes and general advancements. But, be careful here. Do not expect that your Public Cloud environment will 1:1 behave like your TEST environment did before. Be on the safe side and reserve some time and budget for regression testing when taking the step from TST to UAT environment. I’ve seen SSIS errors on Public Cloud environments which never occurred in a TEST environment.
-
Custom interface tables based on event triggers as an alternative for outbound business logic
It seems obvious to leverage the out-of-the-box SQL change tracking capabilities when only updated or new records are to be shipped. It also seems obvious to implement business logic at interface run time. But do not make these decisions too quickly. Weigh all the pros and cons of the different options as there are more options with the framework than you think. For example, in my project I faced a scenario in which it was a requirement to ship out all unique AX7 barcodes to a legacy system. So all new unique barcodes were to be gathered from a multi-company situation (barcodes are company-specific) and additional business logic was needed to gather additional information. I could have leveraged SQL change tracking and implement outbound business logic. But that would have made the interface fairly slow. Instead, I implemented business logic on event basis: whenever a barcode was inserted, business logic evaluated the cross-company uniqueness of the barcode, gathered the additional meta data and inserted this data into a custom interface table when evaluated positively. The result: fast interface export.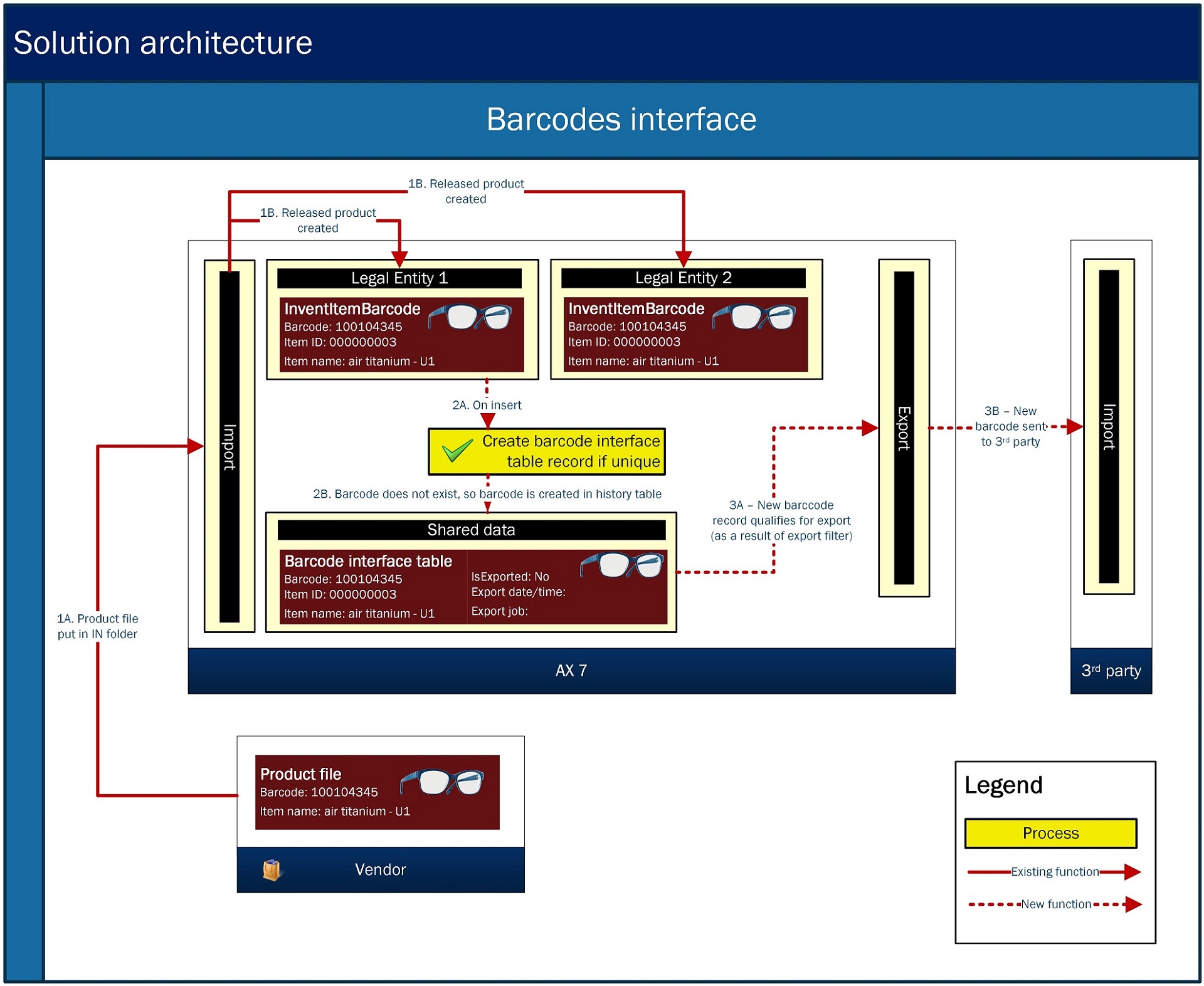
-
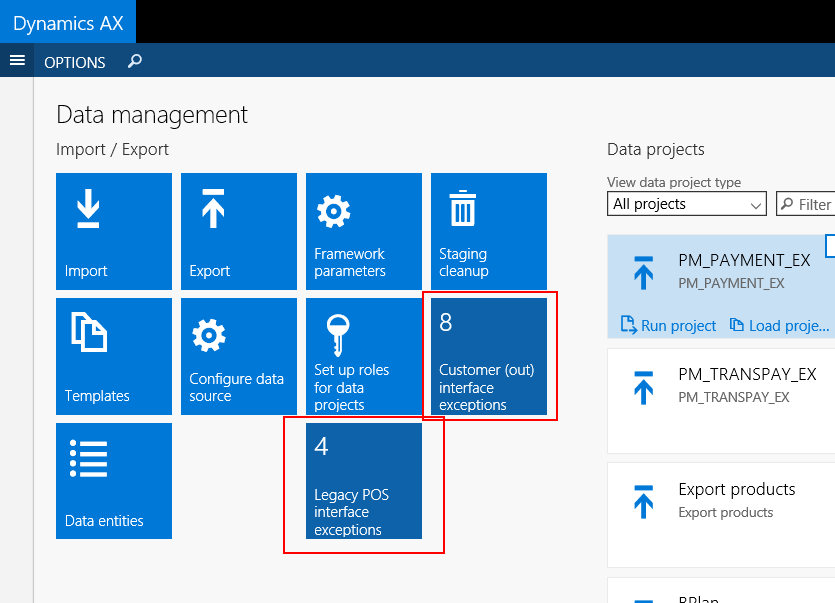
Management-by-exception and 1-click troubleshooting
While building experience with AX7 Data Management, my customer quickly came up with feedback that they expected a dashboard showing all exceptions and 1-click troubleshooting capabilities. So I analyzed their requirements versus the current AX7 Data Management capabilities by creating a diagram highlighting the steps required to troubleshoot the most common scenarios:
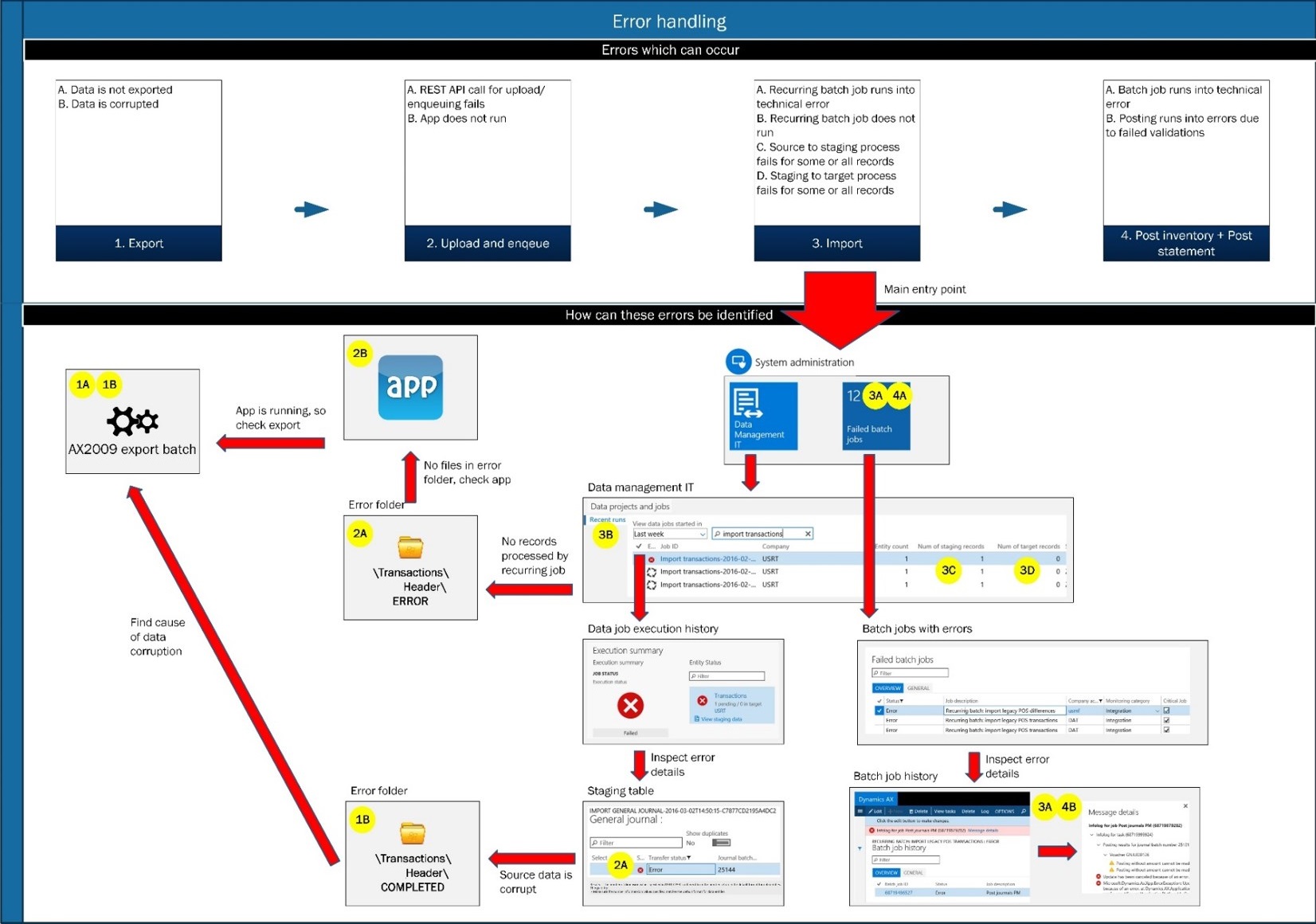
My main conclusions:
• It requires a minimum of 3 clicks to retrieve the cause of an error.
• There’s no form in the AX7 Data Management area which allows for creating personalized tiles to show interface exceptions.
• The Recent runs tabbed list on the IT data management workspace does not provide a complete overview of meta data – Some critical information is missing, for example:
- The list does not show the number of records in the source file, so it is difficult to identify source to staging errors.
- The list only shows the status for the data job run as a whole, but often a job run concerns multiple data entities, which all have their own individual status.
• It is not possible to retrieve the original file name in case a file has been uploaded through the Data Management API. Therefore, it is not possible to trace an (erroneous) data job run back to the original uploaded file.
So I decided to design a new parent-child inquiry form which shows all possible meta data for all interface runs:
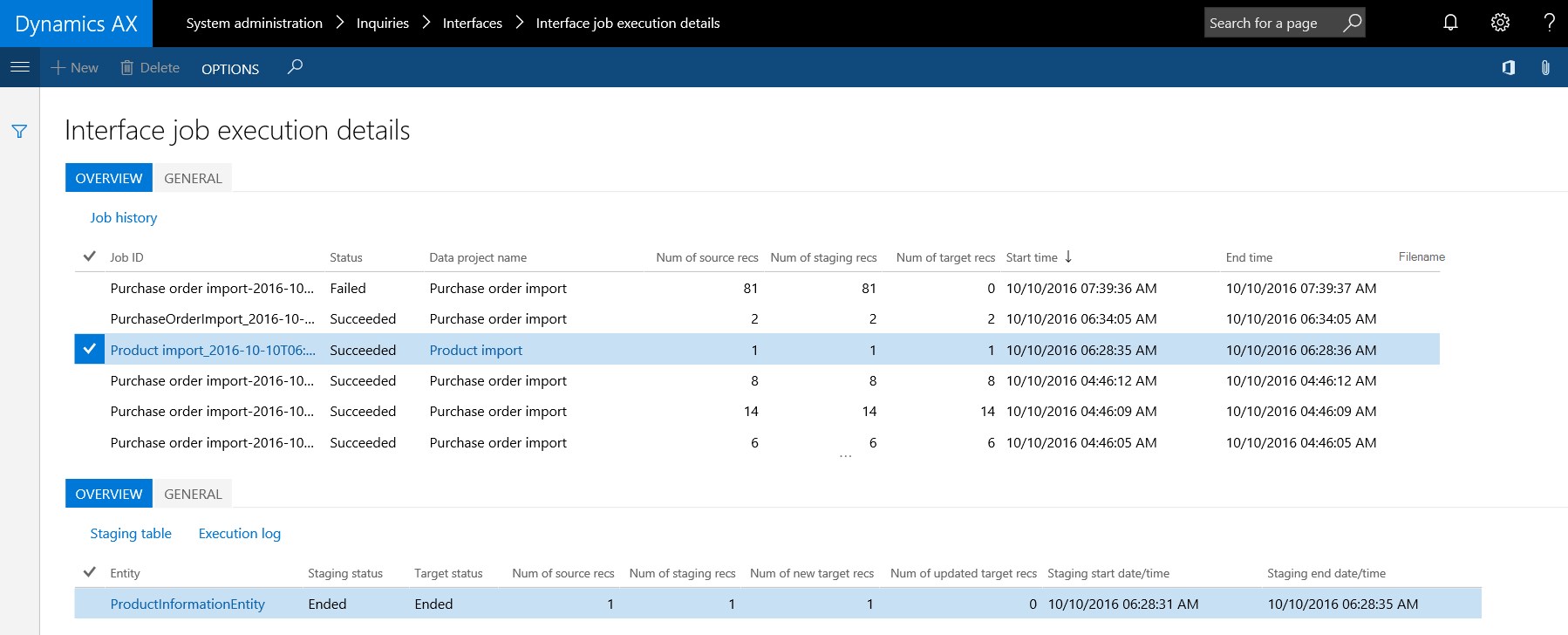
As it is an inquiry form, the user has the ability to create a personalized filter on a single interface, group of interfaces in any status or group of statuses. As per standard AX7 functionality, the filter can be turned into a tile which can be placed on any workspace and pinned to the main dashboard:
So in case an exception occurs, a tile highlighting interface exceptions will show value 1 or higher after refresh. This is the trigger for a system administrator to take action. A click on the tile will directly show the exception in the interface form. By the meta data in the form the system administrator will have a good sense about a possible cause, so he can perform a direct click to the relevant error log (execution log or staging table log). So it will only require 2 clicks to inquire the cause of any error. The challenge here then is to get the number of exceptions down to 0 again after fixing the issue and re-running the respective data job.. ;-).
- Staging table errors in outbound interfaces
Some of you might question why it would be needed to set Skip staging to false on a data project – In other words: to utilize the staging table in an outbound interface process. Well.. it is a requirement if you need to run business logic in your outbound interface.
Although you need to be careful with the implementation of business logic in outbound interfaces, as this can significantly degcrease the performance of your outbound interface, there are scenarios in which you really need it. For those scenarios you need to be aware that outbound staging to target processes handle errors in a different manner than inbound staging to target processes:
- Inbound processes perform validations against standard or custom AX7 business logic. In case of errors, the respective staging record goes into error status and import for the particular record is withheld.
- In outbound processes, custom business logic may put the record into error status, but the export is NOT withheld. AX7 is designed to output the records AS-IS, independent from the status of the record in the staging table.
So if you want to have your outbound staging to target process behave in a similar fashion as your inbound equivalents, here’s my recommendation:
- Implement business logic to validate your data for output as you’d do in an inbound process. So promote your staging records to the status as required.
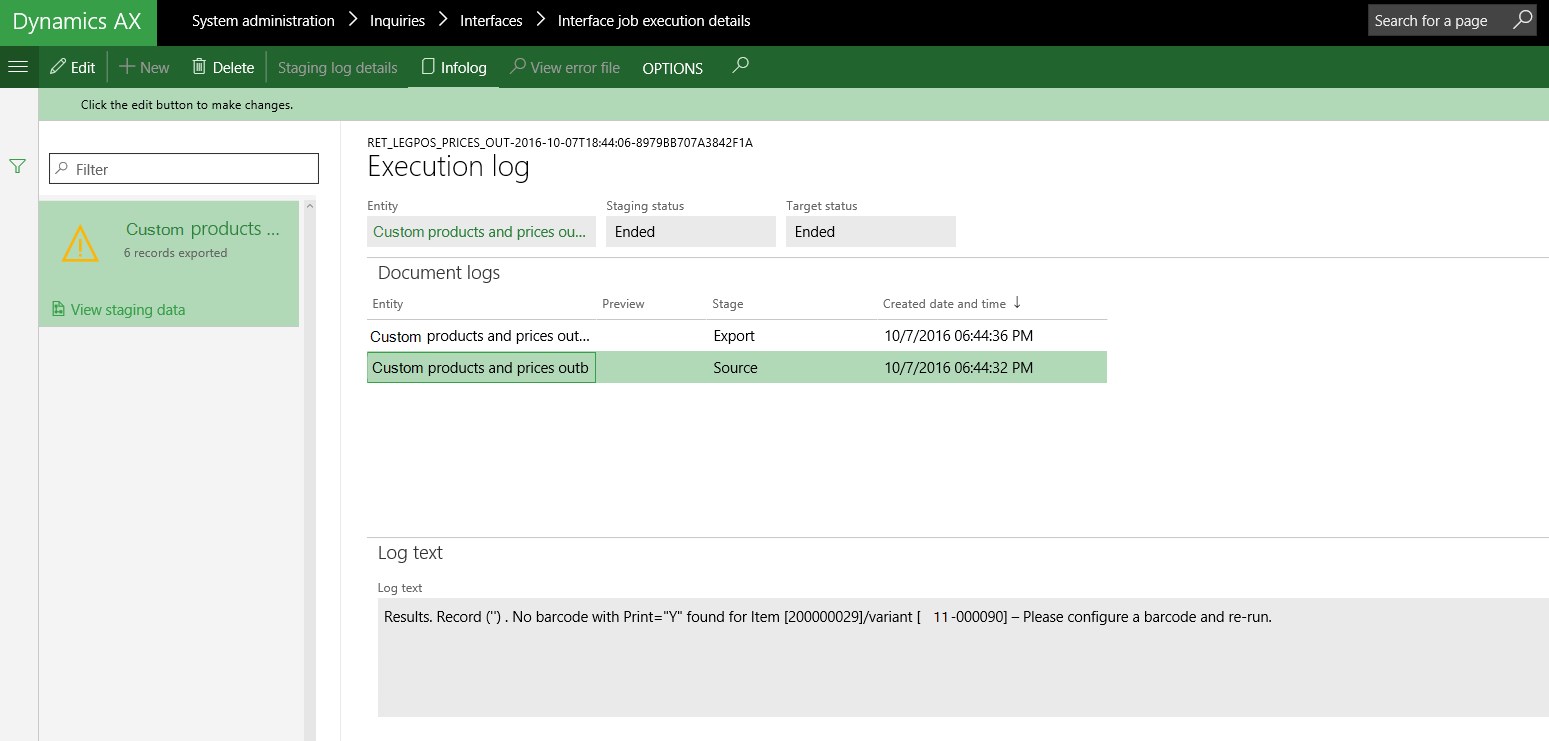
- Implement a routine to delete all the staging table records which are in error state. This will ensure only records which pass your validations are outputted (if you want to allow any output in case of errors).
As a result of this deletion, errors are thrown at Execution log level instead of staging table level:
- Leveraging the power of XSLT transformations
In many outbound interface scenarios, AX7 will have to output columns in a certain order or output specific column names. This can all be handled by using sample files in your data project. But if you need more complex transformations, AX7 offers the ability to leverage XSLT transformations. And these can be really powerful. Some examples:
- Transform root node and main child node names to reflect the required XML schema. In this example the root node “Document” is transformed to “ItemCatalog” and the child node “
”> is transformed to “InventTable”.

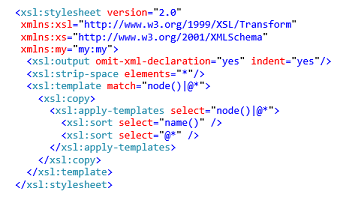
- Sort all XML elements and values in the output XML alphabetically:
-
Minimize non-auto mappings on a data project
When I architecting the various interfaces in my project, I was very keen on including value conversions, default values and other transformations in my data project mappings to provide some flexibility for future adjustments. However, I started to lose enthusiasm when I found out that default values and conversions were not allowed for enums. I even decided to completely push all possible transformations to third-party systems when I found out that mappings cannot be migrated at all. Background here is that with every update on a data entity, you might have to do a lot of manual re-mapping across different environments (DEV, TST, UAT) – see learning 1 above.
Interesting in this context is that if you open the manifest.xml file from a zipped data package, you hit upon the placeholders for the mappings and transformations. But they’re simply not populated as per the current functionality:
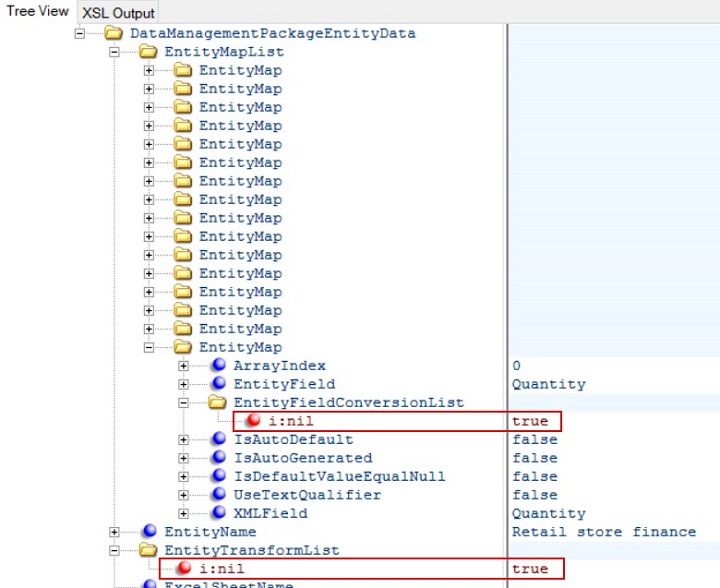
Therefore, I’d advice (for now) to reduce the use of sample files (non-auto column mappings), default values, transformations and value conversions to a minimum. -
Be careful with LOAD PROJECT!
In most demos I have seen concerning AX7 Data Management, interface imports and exports are always run through the data project’s Load Project feature (System administration > Workspaces -> Select data project > Load project). But what they never tell you in those demos is that this feature can completely screw up your interface mapping without you being aware of it. Some examples:
• In case of a component entity, using the Load Project feature will have your child entity mapping removed from the mapping if the child entity is not in the upload file.
• If you deleted an auto mapped column from the interface mapping on purpose, the deleted mapping will have been re-created automatically if you upload the file through the Load Project feature.
• The Load Project feature will cause a mapping for a particular field to be removed if the field was originally mapped but no longer exists in the source file uploaded.
Hence my recommendation for running interfaces manually is as follow:
• Only allow system administrators who know what they’re doing to run interfaces manually through the LOAD PROJECT feature.
• Align the third-party software version, samples files used for unit/functional testing and AX7 data entity software version. This will reduce the risk on issues in the Load Project scenario:
• Teach all other users to run interfaces manually through either of the following methods which will never affect the interface mapping:
a. The Run Project feature.
b. A setup which allows users to drop files in folders which are uploaded and processed through the Data Management API.
-
Export data entity field characteristics
In any integration scenario it is critical to have clear agreement about the interface mapping including the responsibility for data transformations. I always use the following structure for architecting my integrations:
In order to quickly populate the template with the main characteristics of all the data fields in the respective AX7 data entity (field length, field type etc.) I use the following table browser URL:/Default.htm?mi=SysTableBrowser&prt=initial&cmp= &tablename=DMFDefinitionGroupEntityXMLFields&limitednav=true 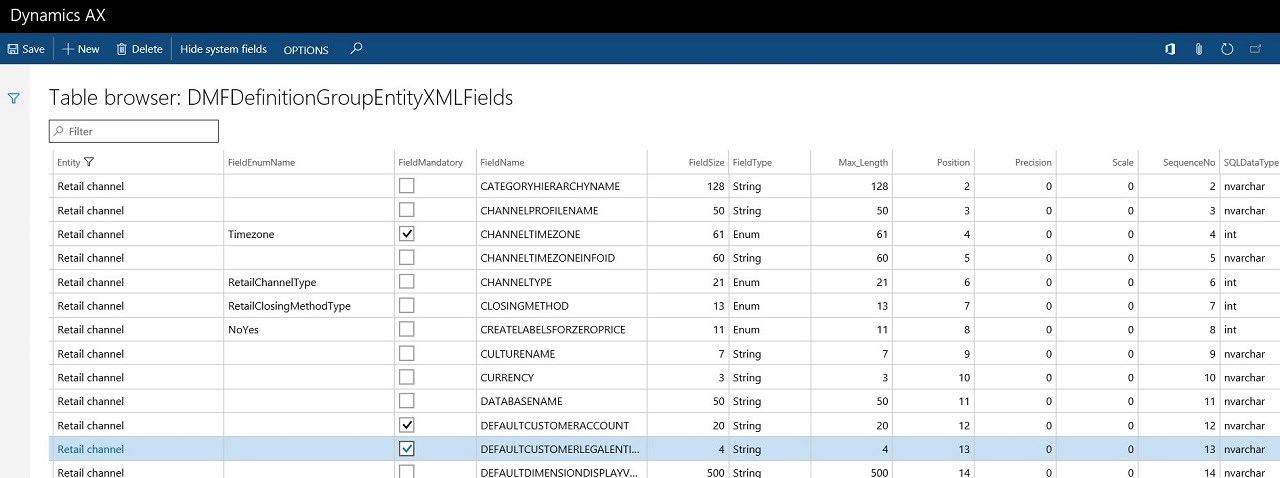
-
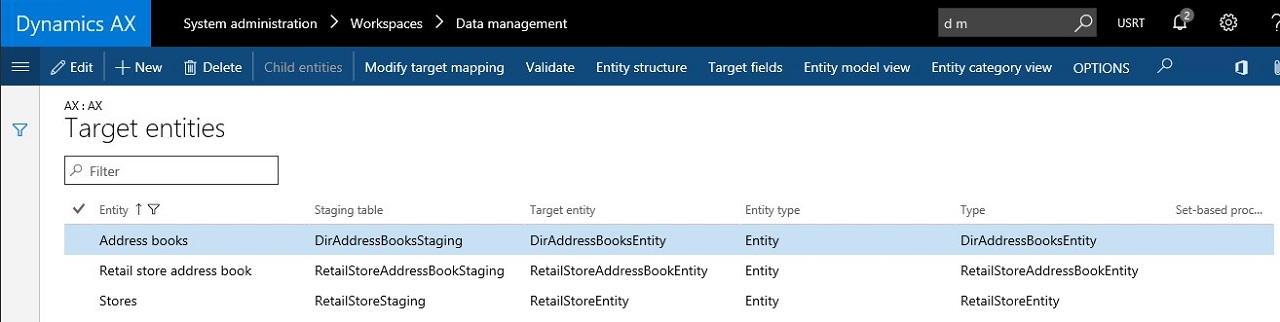
Deprecation of multiple value separator
In previous versions of AX, a ‘multi-value separator’ (for example “,”) could be defined to allow multiple values in 1 column to be imported/exported. In AX7 this is no longer needed due to ‘normalization’ of the list of data entities. A typical example of the classical multi-value import was for example the store/address book association. In AX7, this association is created through a separate data entity “Retail store address book”:
-
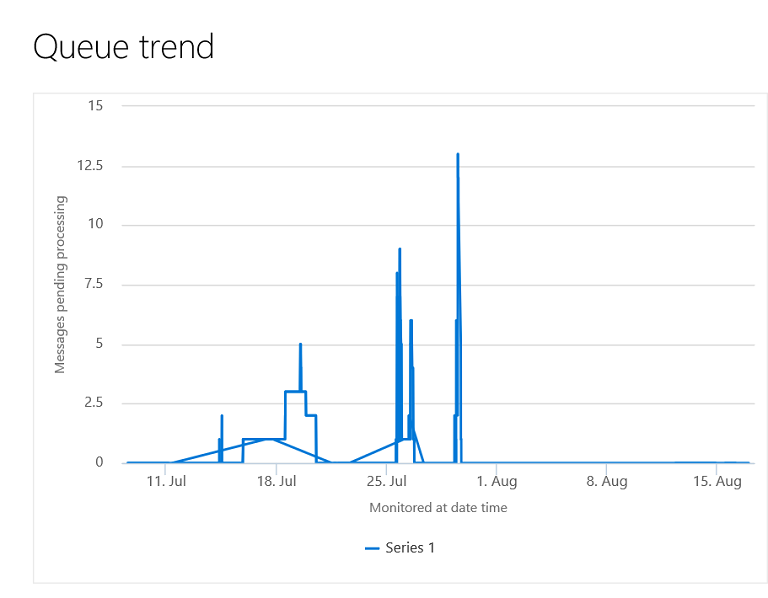
Load monitoring
By enabling the processing monitoring job on the Recurring data job..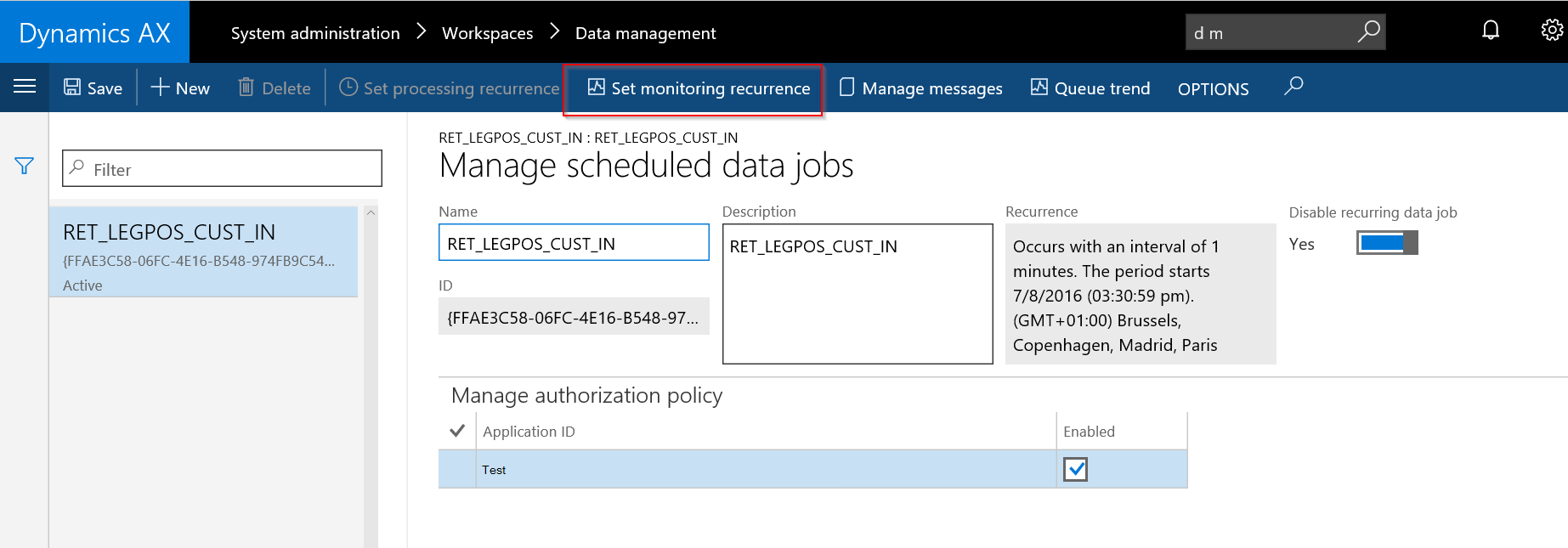
..the Queue trend is populated:
 This enables you to inquire the load and adjust the frequency of the processing job – In case of high Peaks, ensure to run the interface more often to reduce the load per job run:
This enables you to inquire the load and adjust the frequency of the processing job – In case of high Peaks, ensure to run the interface more often to reduce the load per job run:
12. Staging table fields versus data source fields
While architecting interfaces it is important to be aware of the relevance of the difference in scope of data between a data entity and its staging table. For example, you may choose to include additional tables and fields for filtering on the data to be exported, but you may not want to make this data available for export.